Monolith to Microservice 4b
Setting up the monolith pipleine (Azure DevOps Pipelines)
In Episode 1, we created a Monolith application in .NET Core two do some simple Maths on two supplied numbers.
Episode 2, we showed how to use Docker and Dockerfiles to docker-is the application ready to run either on a Developers Laptop or on a Docker Host or Docker Cloud Provider.
Episode 3, we then created a private docker registry so we can store that image and make it accessible to other team members, or other users.
Episode 4a showed how to add tests you can run on your laptop to get quick feedback if you subscribed to the TDD testing methodology.
We’re going to start build our string of automation as part of a Continuous Integration pipeline now. One of the principles I stick to is at every part of the pipeline try to get it to fail fast before doing long winded automations. Don’t aim to fail, but if you do fail fast, get the feedback back to the dev in question as quickly as possible.
To me that means two pipelines. The first one we’ll effectively repeat the tests done on the dev machine but in a “clean room” environment. We’ll do a run through the tests we’ve set up, and then do a compile. If both of those pass we then do part 2 and wrap up those build artefacts into a docker container which we can push to our registry, the longer part of the two steps.
I’ve chosen Azure Devops for this as its simply what I’ve been using this year, there’s no reason this couldn’t be run in a Jenkins, ConcourseCI, OctopusDeploy etc… It’s free for Open Source teams, or small projects less than 5 people. You get a number of hosted agents that we can use to run actions with and configure or you can host your own build servers and craft the build to help with preloading dependencies to speed up the pipeline as a whole. Personally I prefer the hosted agent route, assuming nothing and having to put your dependencies in place first.
As you’ve probably noticed through the series I’ve hosted the code inside Github. We’re going to link the two so that on commit to the GitHub repo, it’ll trigger the pipeline to start testing (and if successful deploying to the Docker Registry).
Lets get started.
- If you don’t already have one, get an account on www.visualstudio.com
- Create a New Project.
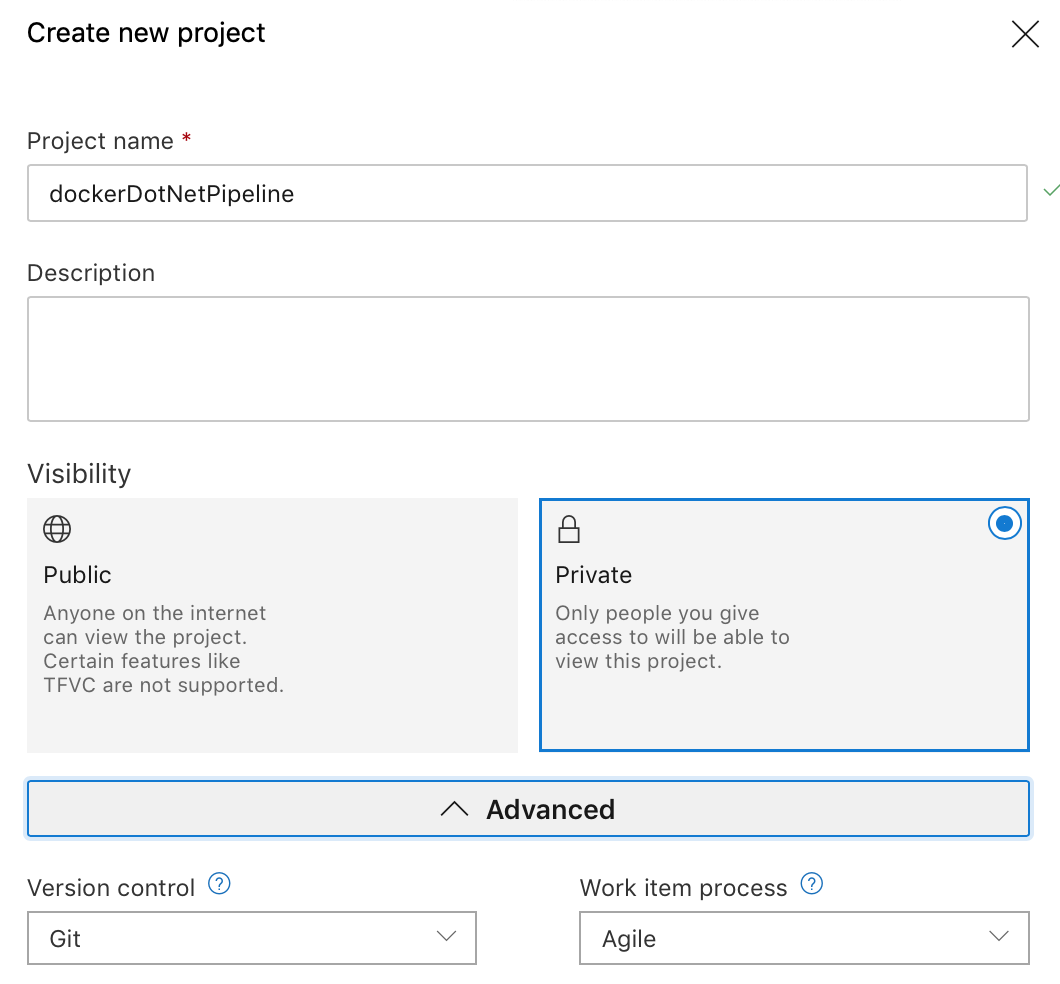
Choose if you want it public or private.
- In the left hand pane, navigate to Pipelines and click New Pipeline.
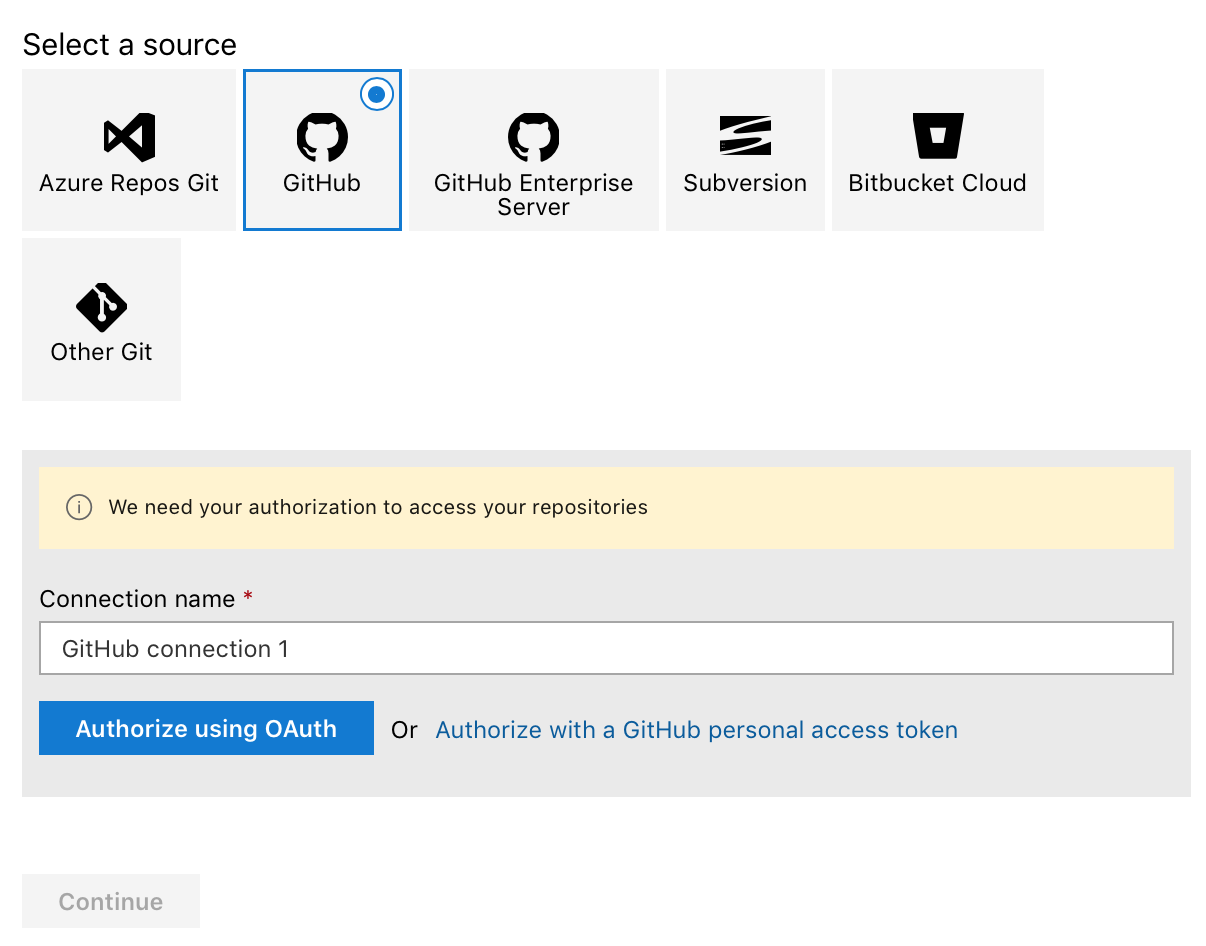
Here we can tie up Azure Devops to a number of different source control services. Here I’ll choose GitHub, and follow the OAuth process. Once done, you can connect to any of your repositories.
There are a number of templates provided for various languages. Our project is a .NET Core one, so pick ASP.NET Core template

First look at the template will look like this:
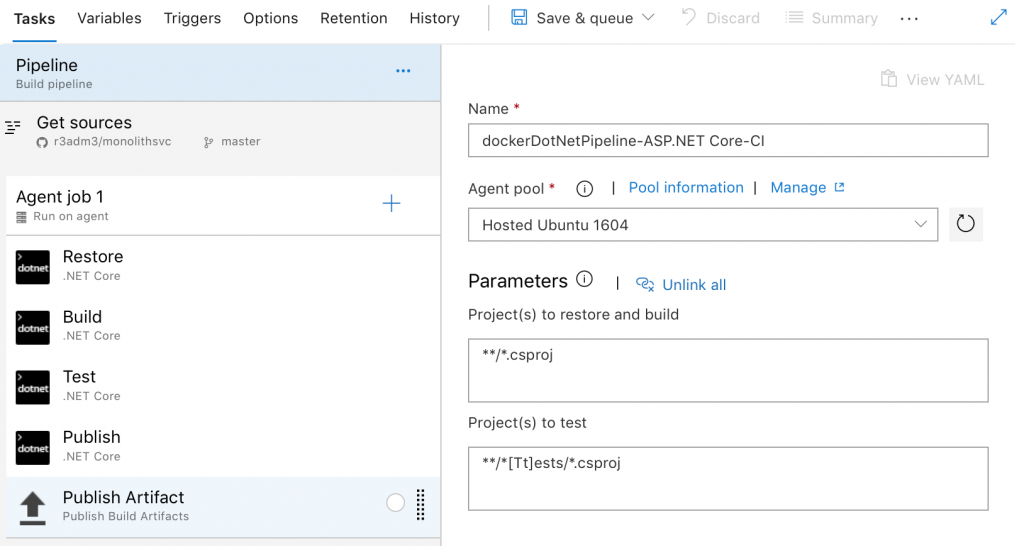
Change the name to something a little more obvious.
The Agent Pool is the collection of Microsoft provided Agents where build processes can run. Here our build processes are set to run on a Ubuntu 16.04 machine with a set of dependencies (there’s some docs on what is installed on those machines). You can set it to Windows hosts, Mac hosts whatever is best for your pipeline. For this project, leave it on the Ubuntu 16.04 Agents.
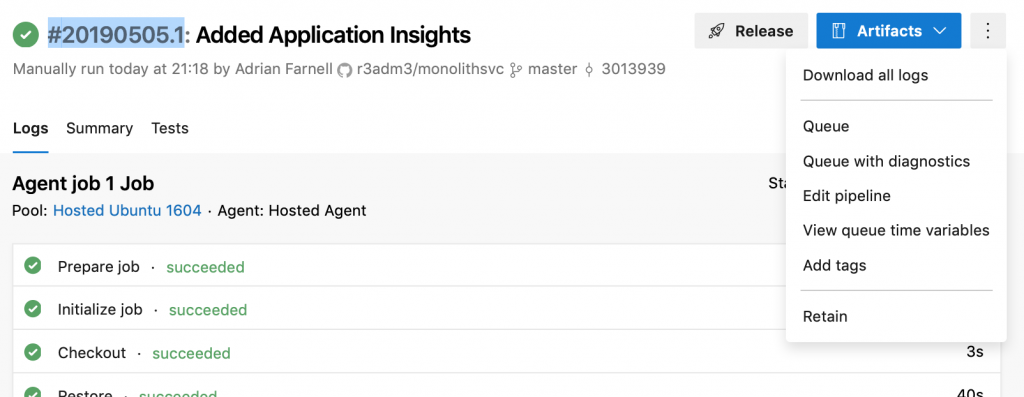
Because its a fairly simple .NET solution, the default settings in the pipeline should be enough to get going. So click Save and Queue to save this set of automations and queue them up to run on the next available agent. When it starts, you’ll see Azure Devops show a build number like this: #20190505.1 which you can click on and watch the logs, really good for troubleshooting.
A good run will look something like this:
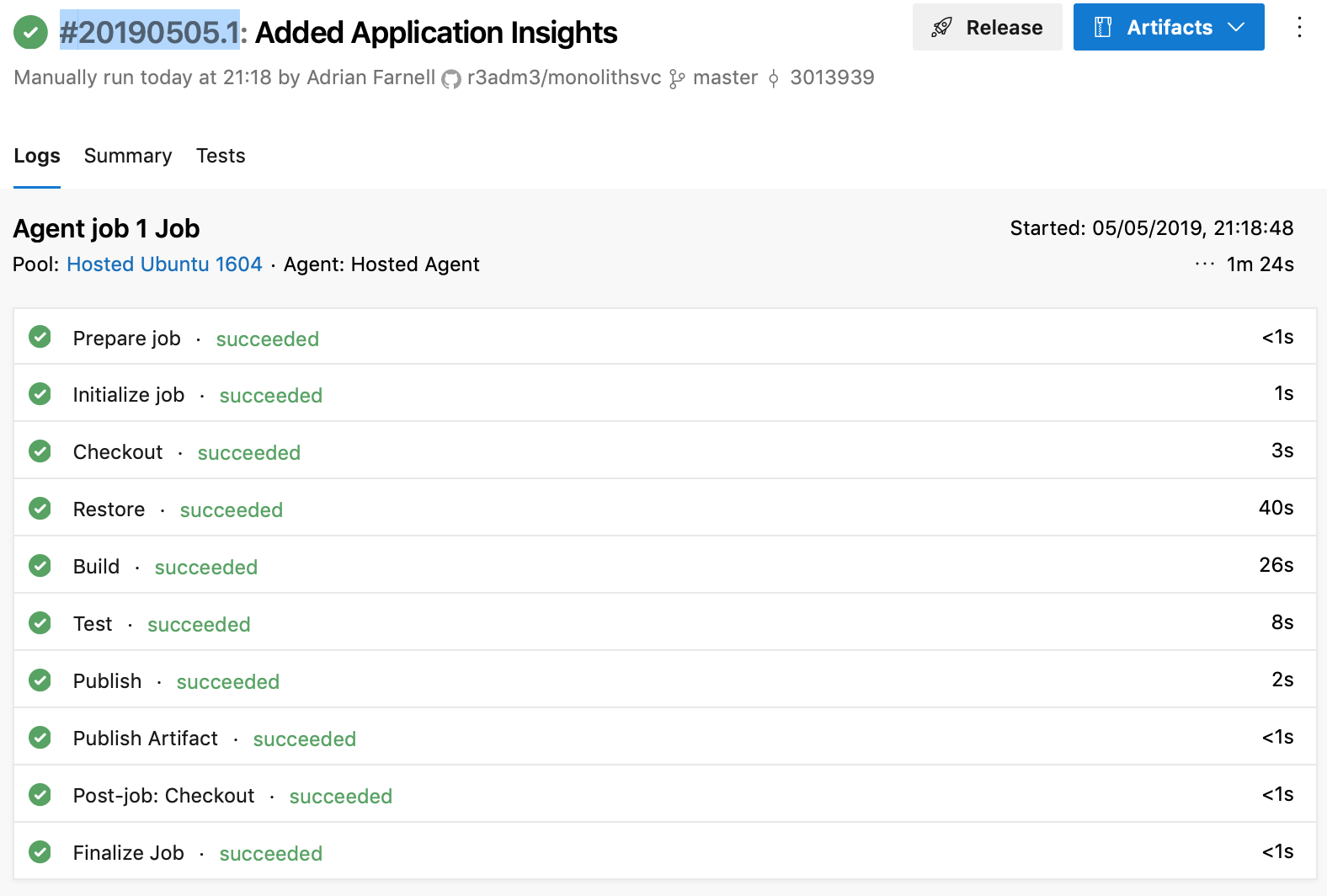
You can amend this pipeline to add in Static Code tests, Style tests, Security Tests (sonar cloud for example), Early Integration tests you name it. I’ll probably add in some other articles on how to integrate with other code check systems another time.
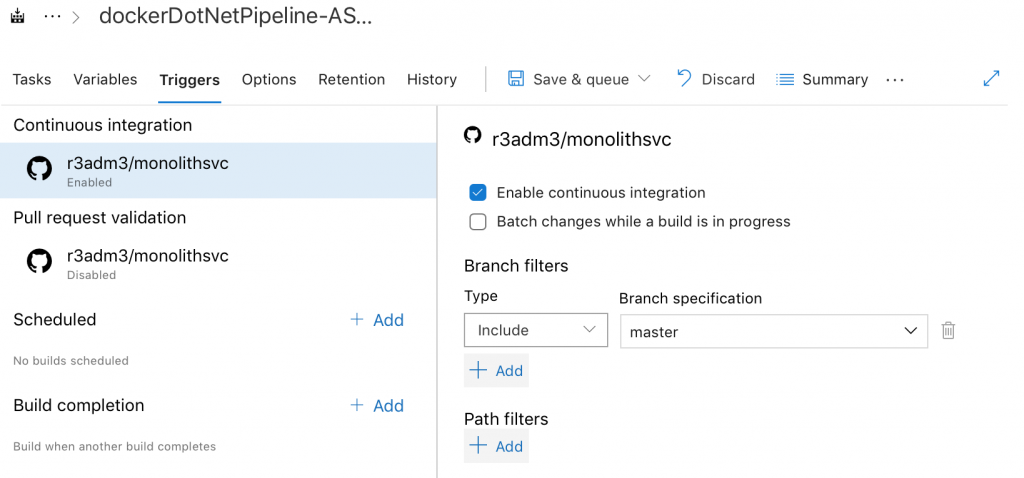
To trigger the pipeline on commit, go back and Edit the pipeline again.
Its as simple as clicking the “Enable Continuous Integration” box.
So to summarise up to here, we have a pipeline that runs when ever a member of the developer team commits to a source repo. Tests run, and compile is done which if it fails can return feedback them on failure. Ideally, as part of their development workflow they shouldn’t check in until the code compiles and tests correctly on their machine.
If we had a more complex development workflow involving branching and pull requests, we can actually run these tests before the merge of code happens between branch and mainline. Again, an article for another time.
Our second pipeline is going to generate a docker image as a build artefact. Create a new pipeline, picking the same repository as the first pipeline.
Choose the Docker Container Template this time.
We need to add our private registry in to place (unless using an Azure Registry).
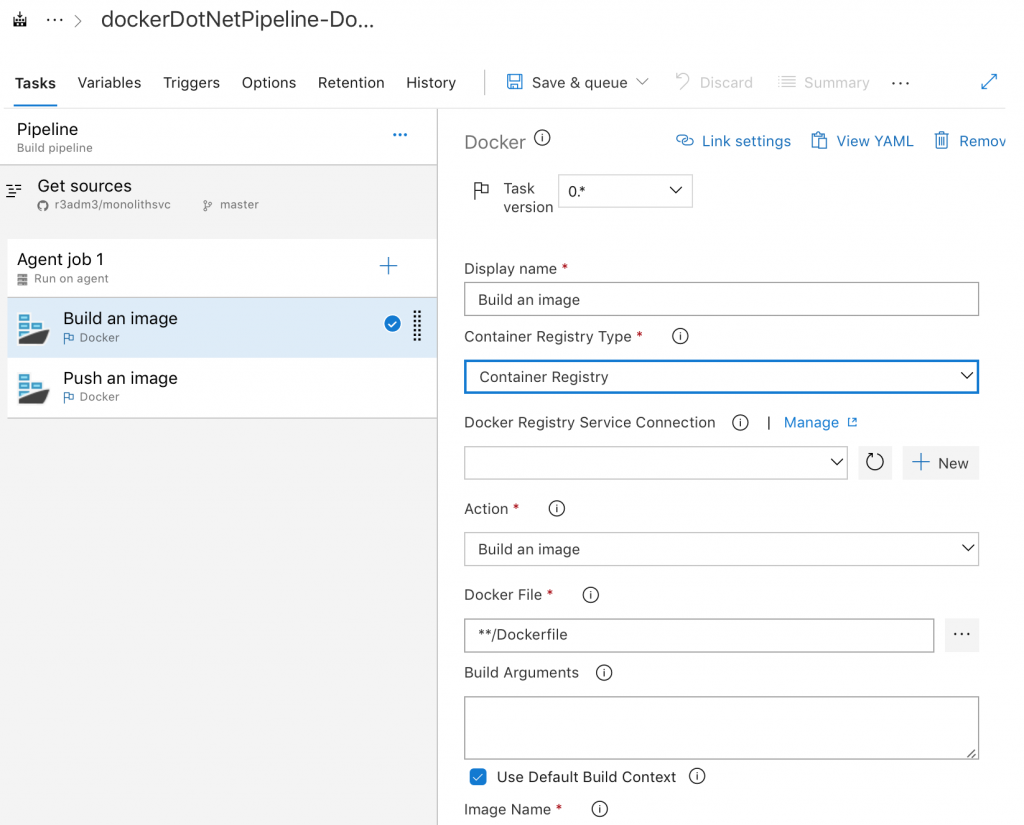
Container Registry Type, select Container Registry. Docker Registry Service Connection click New.
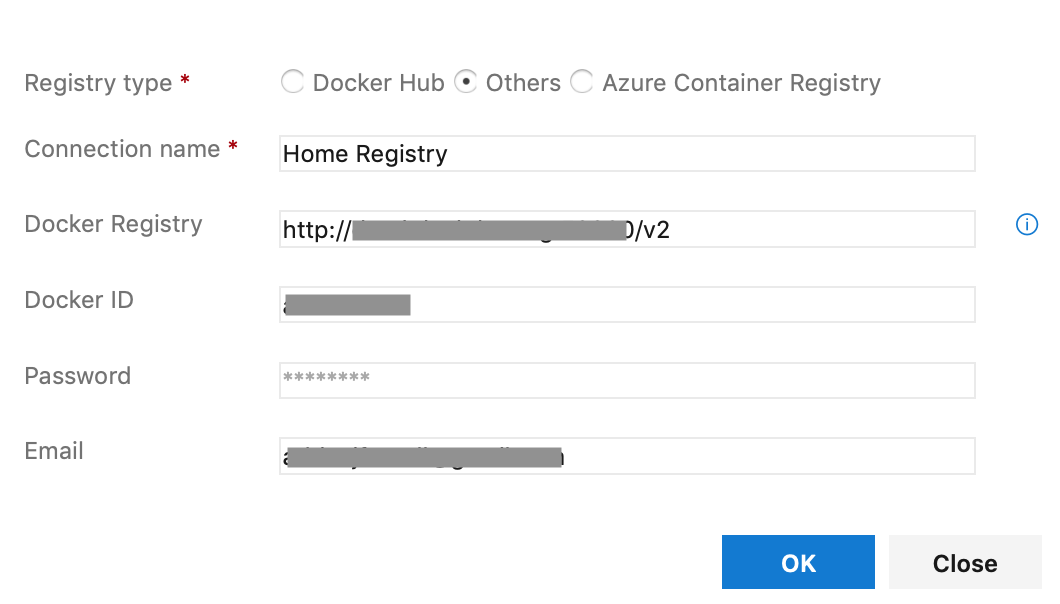
Once the connection is setup, we can now get the docker commands to build an image. If we were doing this locally if you remember we run the following command:
1docker build -t remotehost/monolithsvc:latest .
Since this is an automated process, we should add a tag for traceability to ensure we have an audit trail of which docker image was created by which run of automation. If you notice in the image name text box this is where we put the tag name in. The $() sections are strings Azure DevOps insert at runtime. Remember if your using docker push to a remote registry, the remote registry hostname needs to be part of the tag.
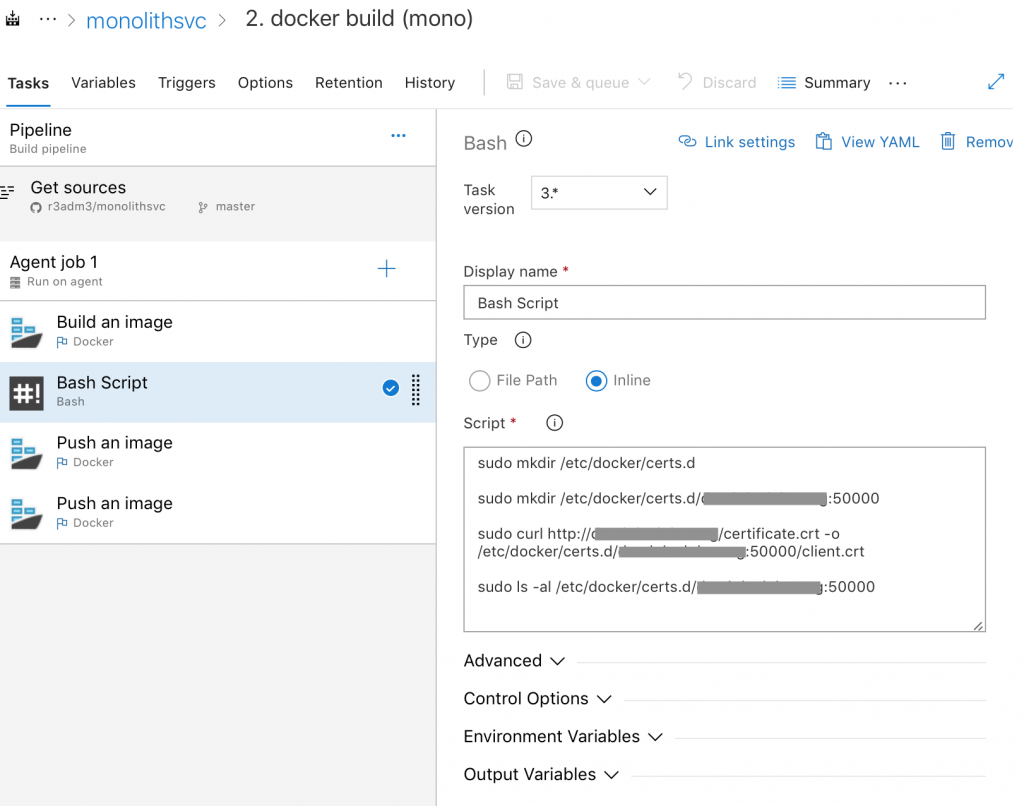
As a bit more of a complication, Azure DevOps requires SSL/TLS to be setup correctly on the remote registry for it to work properly. We have to add in a bash script just before we do the push to make sure our Azure Agent trusts the remote registry.
1sudo mkdir /etc/docker/certs.d
2
3sudo mkdir /etc/docker/certs.d/remote.hostname:50000
4
5sudo curl http://remote.hostname/certificate.crt -o /etc/docker/certs.d/remote.hostname:50000/client.crt
6
7sudo ls -al /etc/docker/certs.d/remote.hostname:50000
I pull in each of the certificates from a remote web server at this point.
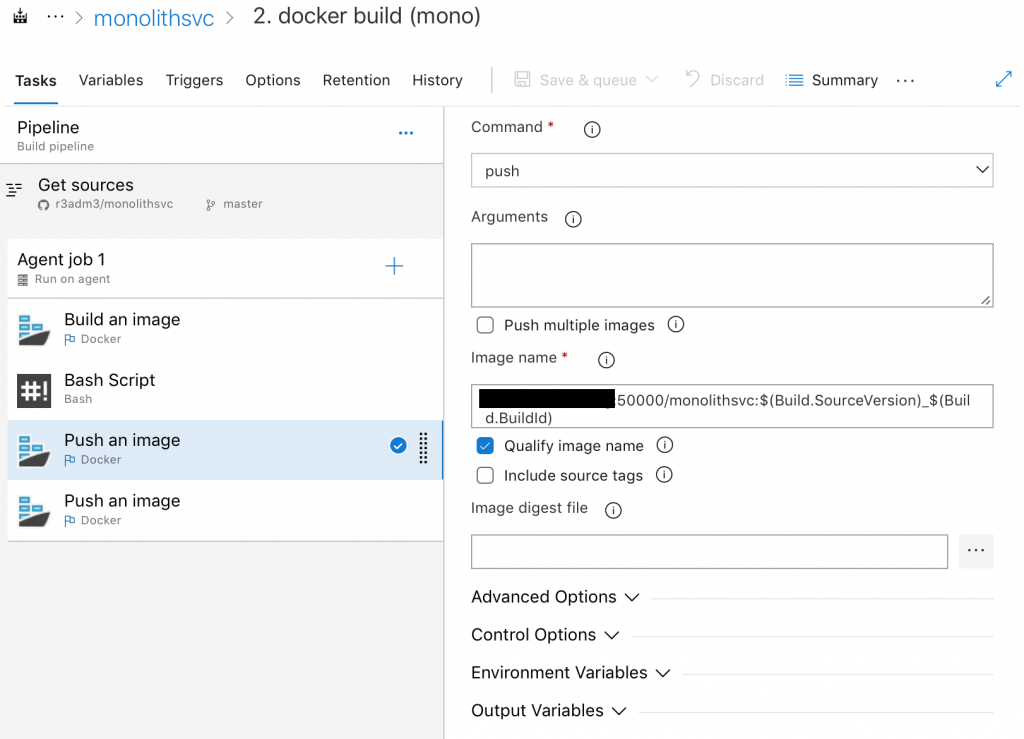
Once that’s done, we only have the Push to do now. There are two in the above flow so that one is tagged to be “latest” and the other is tagged with the source control Id’s. (Docker is smart enough that it’ll know that both images are the same and only needs to do one upload due to hashing of the image).
…and that’s it.